Every data analytics journey begins with data. Therefore, at Datrics, we are constantly improving our data connectors. In the latest product updates, we have redesigned the dataset creation screen, so that it’s more convenient to write queries and explore the uploaded data, added connectors to MongoDB and Redshift.
MongoDB Connector
MongoDB is one of the most advanced cloud database services, with data distribution and mobility across AWS, Azure, and Google Cloud, built-in automation for resource and workload optimization. MongoDB connector in Datrics is used to read data stored in noSQL database. Export data brick also supports MongoDB databases.
How to import data from MongoDB to Datrics?
MongoDB connector in Datrics is created to retrieve data from the no-SQL database for further analysis. MongoDB databases store data in a binary JSON format called BSON.
To configure the connector, create a MongoDB data source. Data source will be used to retrieve data and export data to MongoDB.
Data source configuration:
- Host
- Database
- Port
- User
- Password
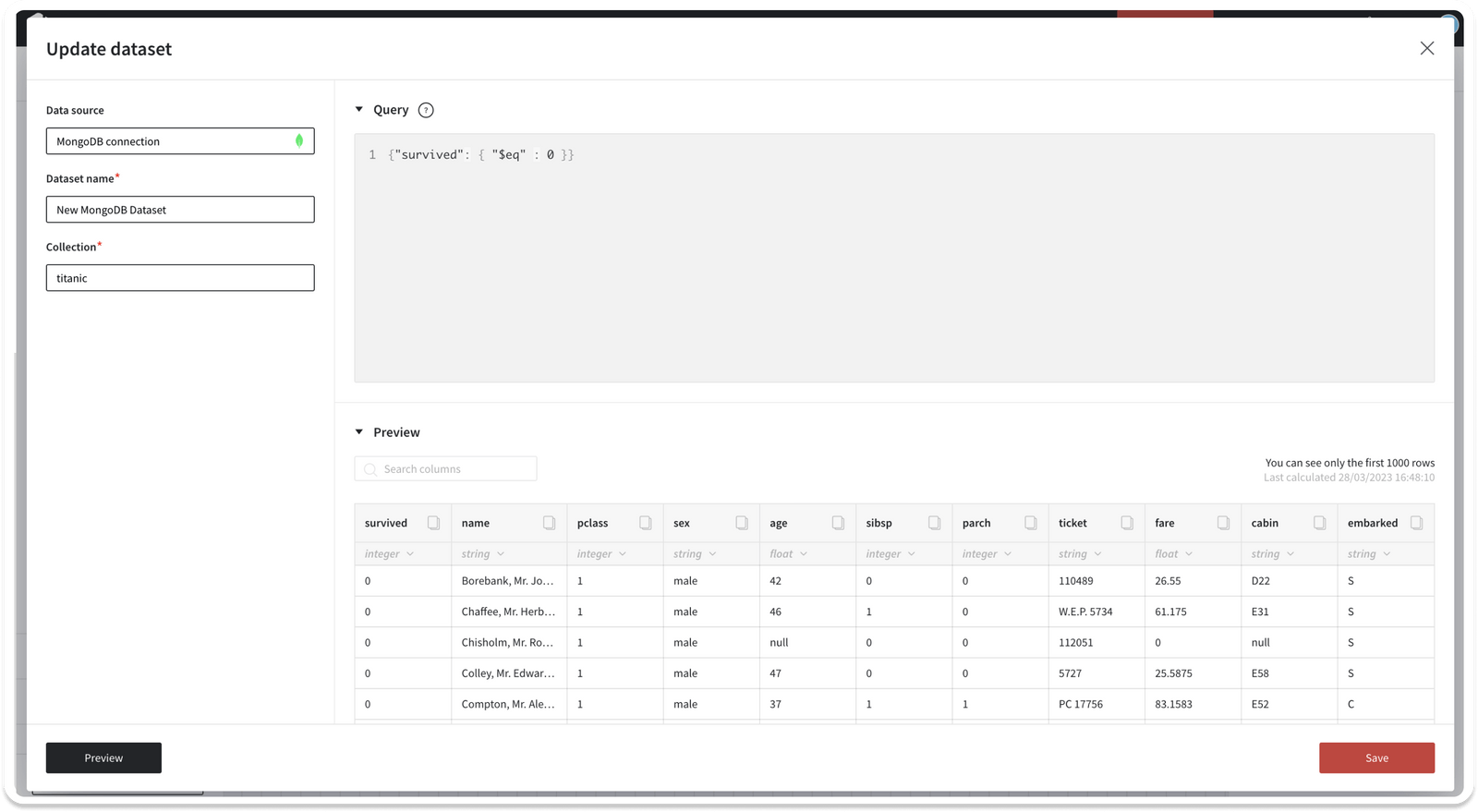
After datasource creation, you may create the dataset for MongoDB. Dataset may include the data from one collections. Datrics MongoDB dataset configuration:
- Datasource
- Collection
- Query
Query is the representation of the MongoDB find() method.
Connector transforms documents from noSQL database into the pandas dataframe.
How to export data to MongoDB using Datrics connector?
Datrics provides export connector to MongoDB. Connector transforms pandas dataframe to JSON supported by noSQL database.We have added MongoDB data source to the Export Data brick. Export connector configuration:
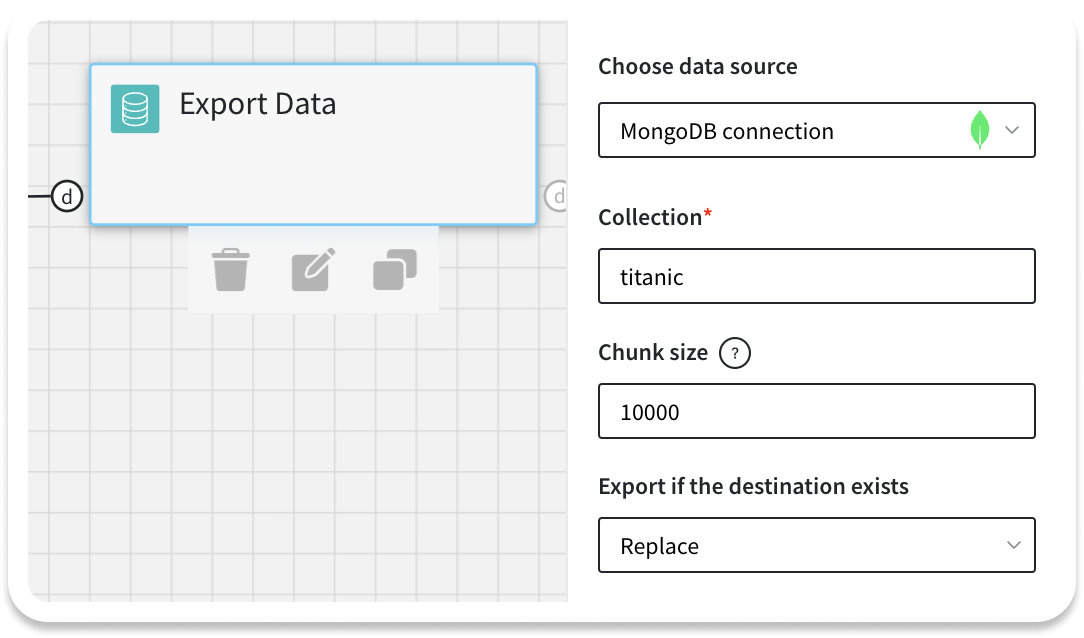
- Data source
- Collection
- Chunk size
- Behaviour is the destination collection exist:
- Append documents to collection
- Replace collection
- Fail export
Redshift connector
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and machine learning to deliver the best price performance at any scale.
Redshift is popular data warehouse for data systems on Amazon infrastructure and now you can use it with no-code analytics in Datrics.
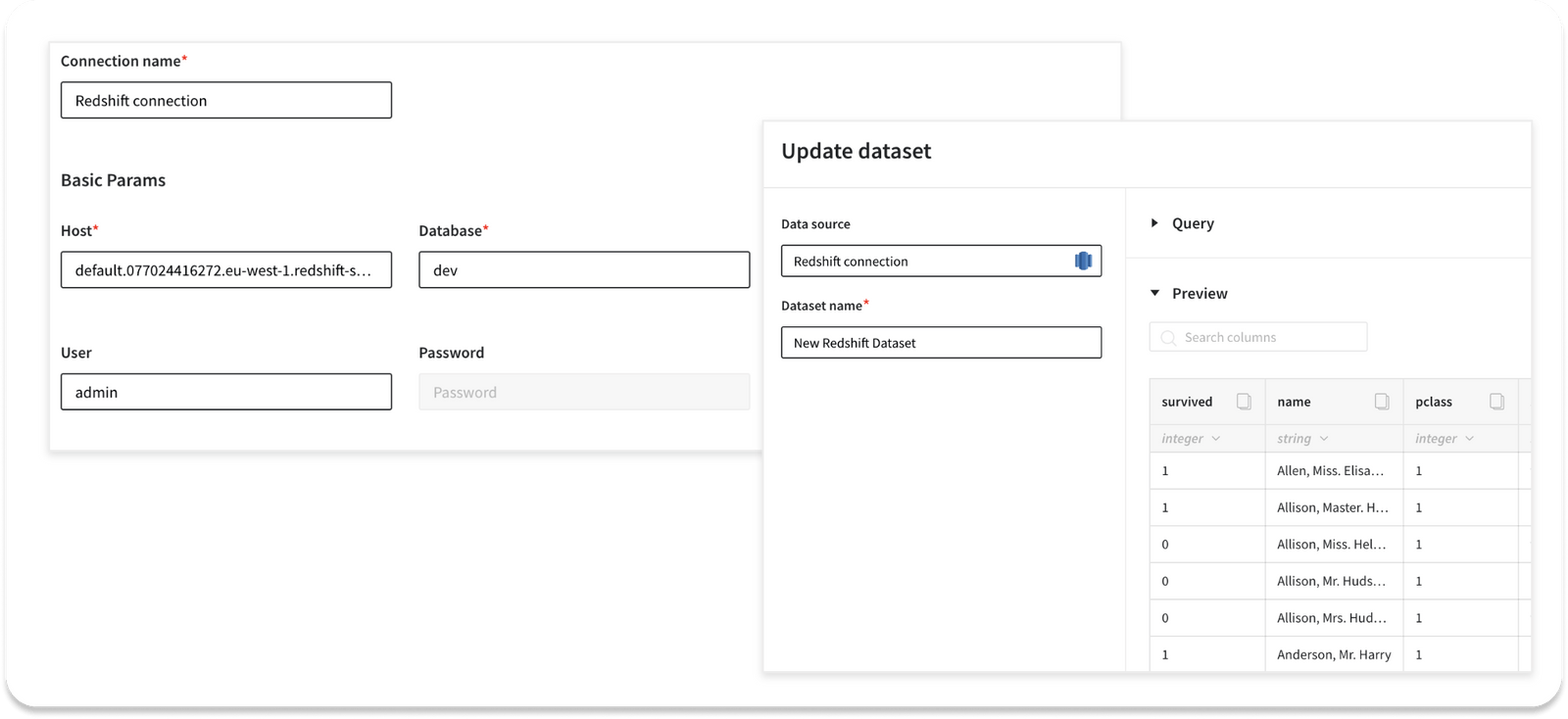
To retrieve the data from Redshift, create the data source with your authorization information, and then create the dataset.
Lately we have also created connectors to AWS S3 and Google Cloud storage, and Amazon Athena.
Export to DB schema
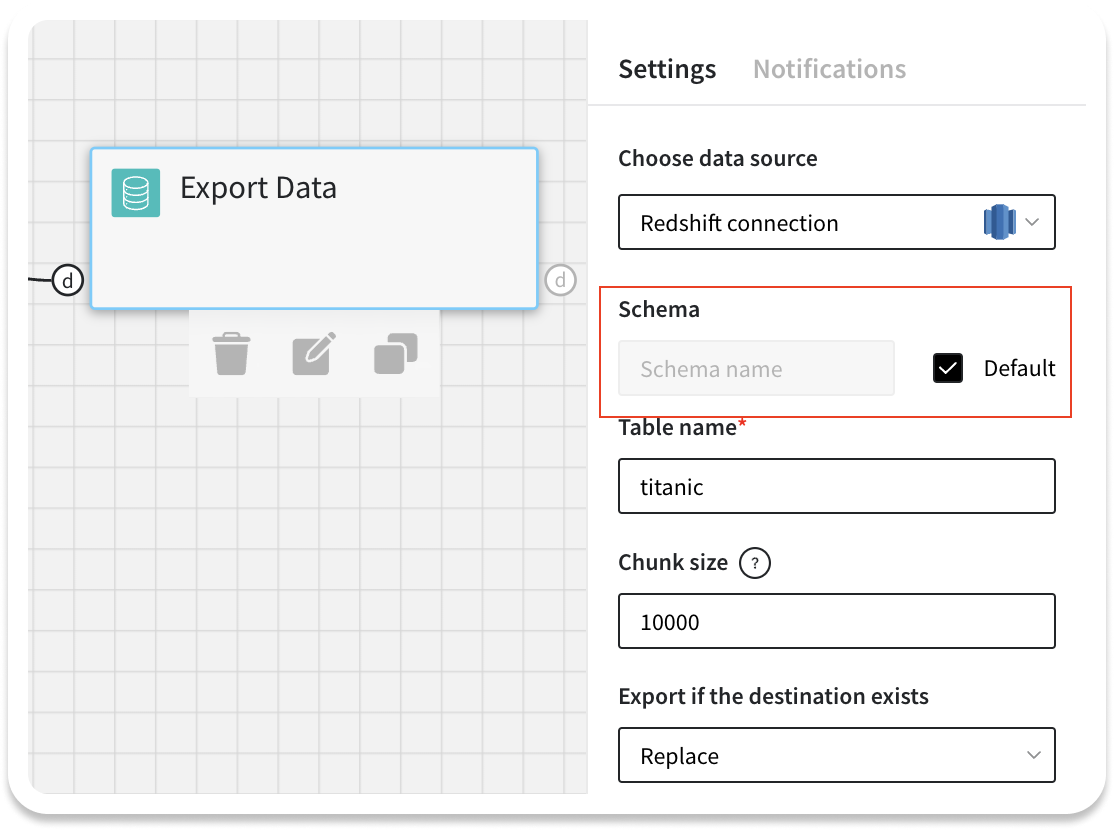
And last, but not least, most of the databases on the market support multiple schema set up. Therefore, when exporting the data it may be important to define the specific schema where the target table is placed.
By default, we are going to work with the default schema of the database. If you are not sure which schema to use, it’s preferable to leave the default setting. However, if you want to specify the schema manually, uncheck the ‘default’ setting and type the schema name from your database.
In the latest update we have also improved the design of the Export Data brick. Currently, along with connection name, the connection type is displayed.